Содержание статьи:
- Что такое пагинация;
- Какое значение пагинация имеет для SEO-специалиста;
- Использование метатегов <meta name=”robots” content=”noindex, follow” />;
- Использование rel=”canonical” с указанием на первую страницу;
- Использование rel=”canonical” с указанием “сама на себя”;
- Canonical на view all;
- Закрытие от индексации и динамическая пагинация;
- Clean-param;
- Как же поступать в итоге;
- Итого.
Что такое пагинация?
Пагинация, это способ разделения контента сайта на страницы для удобства пользователя. Существует несколько общепринятых способов управления пагинацией:
- Ниже представлен пример классической постраничной навигации с нумерацией и кнопкой перехода на следующую страницу;

- Кроме того, могут использоваться "бесконечный скролл". Его можно наблюдать в ленте социальных сетей, а так же на некоторых интернет-магазинах. Когда пользователь докручивает ленту до конца, новый контент догружается автоматически и пользователь может скроллить далее;
- Динамическая подгрузка контента с помощью кнопки "показать еще". Наиболее часто используемый вариант на интернет магазинах в комбинации с классической постраничной навигацией. Клик в кнопку "Показать еще" динамически подгружает контент на страницу без перезагрузки.
Независимо от метода, любое разделение на страницы делается в первую очередь для удобства пользователя. А так же для оптимизации ресурсов сервера и интернет-трафика (загрузить список с 30 товарами или 10 статьями значительно проще, чем загружать весь товар или все статьи раздела на страницу). С точки зрения UX всё понятно, а как на счет поисковых систем?
Какое значение пагинация имеет для SEO-специалиста
Пагинация — это один из инструментов, позволяющий управлять правильной индексацией и сканированием элементов (товаров, статей и тд.) сайта, а также является одним из способов показать ассортимент сайта пользователю и поисковым системам.
Об управлении правильной индексацией и сканированием стоит сказать чуть подробнее. Необходимо осознавать, что существуют различные типы сайтов и различные тематики, в которых может (и даже, наверное, должен) использоваться различный подход к настройке пагинации. И SEO-специалисту необходимо понимать, почему и зачем стоит использовать тот или иной метод оптимизации при продвижении сайтов и к чему приведет неправильная настройка.
Относительно свежие изменения в алгоритмах поисковых систем о которых стоит знать.
- Google больше не интересны rel=”next” и rel=”prev”.
То есть, якобы rel=prev/next ушел в отставку, так как Google и без него на основании других сигналов умеет определять страницы постраничной навигации на сайтах. Да, Google использует евристические методы для определения страниц пагинации. То есть на основании определенных признаков, поисковая система понимает что данные URL являются постраничной навигацией. Но, мы со своей стороны добавляя указания next и prev оставляем для поисковиков дополнительные маркеры или подсказки. Поэтому, я рекомендую, несмотря на это заявление, продолжать использовать rel=”next” и rel=”prev на страницах пагинации. К тому же существуют другие поисковые системы, которые всё еще используют данные аттрибуты тега <link>, например Bing.
-
В Google проводился эксперимент, где в сниппетах выводилось число товаров в категории интернет-магазинов - подробнее. Что подтверждает информацию выше. Эвристические механизмы Google отлично работают.
-
Яндекс теперь сравнивает контент на канонических страницах. То есть, если с помощью rel=”canonical” указана каноническая ссылка с одной страницы на другую, контент страниц проверяется на идентичность. И при обнаружении значимых различий, неканоническая страница будет проиндексирована. Почитать подробнее можно здесь - "Неканонические страницы в поиске"
Методы оптимизации страниц пагинации
Использование метатегов meta name=”robots” content=”noindex, follow”
Этот метатег размещают на всех страницах пагинации кроме первой, тем самым закрывая страницы от индексации, но разрешая поисковым системам сканировать их и обходить страницы, на которые эти страницы ссылаются.
В 2017 году Джон Мюллер объяснил проблему данного метода. Страницы с meta noindex в долгосрочной перспективе перестают обходиться Google и follow, образно говоря, превращается в nofollow. Подробнее здесь — Google: Long Term Noindex Will Lead To Nofollow On Links
Использование rel=”canonical” с указанием на первую страницу
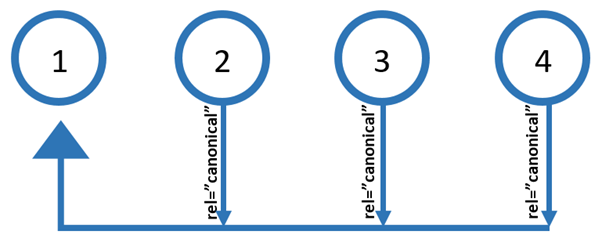
Это один из методов, который был и возможно будет и далее основным методом поисковой оптимизации страниц пагинации под ПС Яндекс.
Сами представители Яндекс всегда говорят, что это оптимальный способ.

https://yandex.ru/blog/platon/2878
При использовании данного метода мы получаем хороший обход роботами ПС страниц пагинации и внутренних ссылок, размещенных на них (нет запретов ни на индексацию, ни на сканирование). Предполагается их отсутствие в индексе поисковых систем (но это не совсем так).
После внесения изменений в алгоритмы Яндекс, страницы пагинации стали попадать в индекс. Т.к. теперь контент между страницами сравнивается, а чаще всего он имеет различия. В итоге страницы индексируются и периодически могут ранжироваться в поиске.
К тому же, из-за этого наблюдаются постоянные “скачки” в индексе:
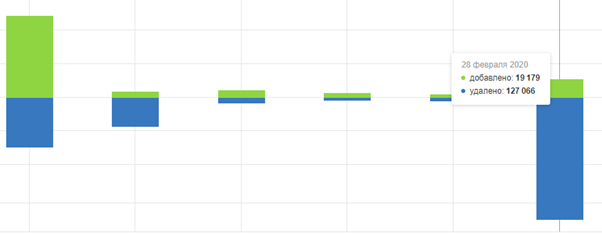
Это усложняет быстрый анализ индексации ресурса, ведь необходимо отсеивать “мусор” в виде пагинаций.
При таком подходе, используемые SEO-оптимизаторами методы оптимизации контента пагинаций, такие как:
- оптимизация тегов title: {тайтл основной страницы или деоптимизированный тайтл основной страницы (срезанный до названия раздела без «купить» и пр.)} + Страница {№}
- аналогичная уникализация description, а иногда и h1;
- удаление текстов со страниц пагинации во избежание дублирования контента;
- внесение др. изменений в контент.
Приводят лишь к тому, что алгоритм видит больше различий между страницами, принимает их неканоническими и добавляет в индекс.
Казалось бы, чтобы попытаться сократить количество страниц пагинации в индексе поисковых систем, необходимо устранить количество различий между страницами пагинации и первой страницей. В итоге, в случае индексации страниц пагинации (они всё равно могут быть проиндексированы, так как листинг товаров на страницах имеет различия), мы получим более сильную конкуренцию в ранжировании между страницей пагинации и основной страницей раздела.
Что касается ПС Google. Они всегда говорили, что данный метод неверный.
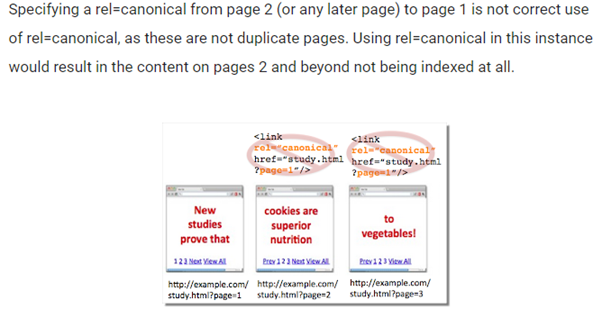
Блог Google - ошибки употребления canonical
Использование rel=”canonical” с указанием “сама на себя”
(страница ссылается в каноникале сама на себя, так называемый self-referencing canonical)
При использовании данного метода, аналогичным образом все страницы пагинации доступны роботам ПС, ссылки со страниц обходятся. Предполагается нахождение страниц пагинации в индексе, соответственно, оптимизатору будет необходимо предпринять действия для того, чтобы уменьшить возможную конкуренцию между первой страницей и последующими. Для этого можно использовать перечисленные в предыдущем блоке методы оптимизации.
“Порезав” оптимизацию страниц указанными методами, они будут реже конкурировать за ТОП в поисковых системах. При этом стоит заметить, что ранжирование страниц пагинации при использовании такого метода чаще встречается в поисковой выдаче Яндекс, чем в Google.
В Яндекс использование данного метода приведет к похожей проблеме, как и в предыдущем методе — “скачки” в индексе (они всё равно будут, но меньше). Страницы пагинации периодически будут добавляться в индекс и удаляться из него, но уже не как «неканонические», а как «недостаточно качественные». Эта проблема так же, как и в предыдущем методе несколько затрудняет анализ индексации страниц сайта.
Google рекомендует использовать данный метод.
Кстати, совсем недавно Google обновил документацию оптимизации интернет магазинов и там отдельно указал на то, что данный метод указания каноникала верный - Читать.
Дополнительно для Google в Google Search Console можно указать:
- GET-параметр пагинатора;
- что этот параметр делает;
- сканировать страницы с этим параметром или нет.
Canonical на страницу view_all
Данный метод настройки правильный для Google.

Использование данного метода не подходит каждому сайту. Если на странице будет 1000 товаров, то обеспечить её быструю загрузку будет практически невозможно.
Закрытие от индексации и динамическая пагинация
Закрывать пагинацию от индексации можно через robots.txt или метатег noindex. Так же от пагинации можно отказаться вообще, заменив её на динамическую (infinite scroll или бесконечная прокрутка).
Так как закрытие от индексации и динамическая прокрутка равносильны и запрещают индексирование и сканирование (уточнение: для гугл закрытие в роботс не означает запрет на индексирование) страниц пагинации и контента на них, я их объединил в один блок.
В некоторых случаях, запрет на индексирование и сканирование страниц может быть оправдан, но об этом чуть позже. Так как рассказывать тут об оптимизации больше нечего (нечего оптимизировать, ведь ничего не индексируется и не сканируется), переходим к следующему методу.
Сlean-param для страниц пагинации
(при условии, что она организована через get-параметры)
Учитывая последние изменения в Яндекс касающиеся атрибута canonical, появился еще один метод (он и был ранее, просто для оптимизации пагинации не использовался широко) — указание для ПС Яндекс директивы Clean-param в robots.txt.
Особенность данного метода в том, что мы не запрещаем поисковым ботам переходить на страницы с параметрами, но и в индекс данные страницы не попадают.

Тут SEO-специалисту необходимо убедиться, что бот совершает переходы по ссылкам, размещенным на страницах с параметрами, иначе использование данной директивы было бы бессмысленным.

Для этого я провёл небольшой эксперимент. Создал тестовый сайт, на котором стоит ссылка на страницу с параметрами, указанными в директиве Clean-param. На этой странице стояла ссылка на другую страницу, которая кстати тоже с таким же параметром.
В итоге Яндекс обошел все страницы сайта. Скриншот ниже:
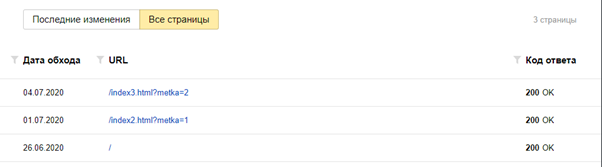
Эти данные подтверждают, что Яндекс обходит контент, размещенный на страницах с параметрами, закрытыми через Clean-param. Но данный эксперимент не отвечает на вопрос, «а как часто он будет переобходить данные URL?», что очень важно.
Для ответа на вопрос нужен эксперимент с анализом логов сервера:
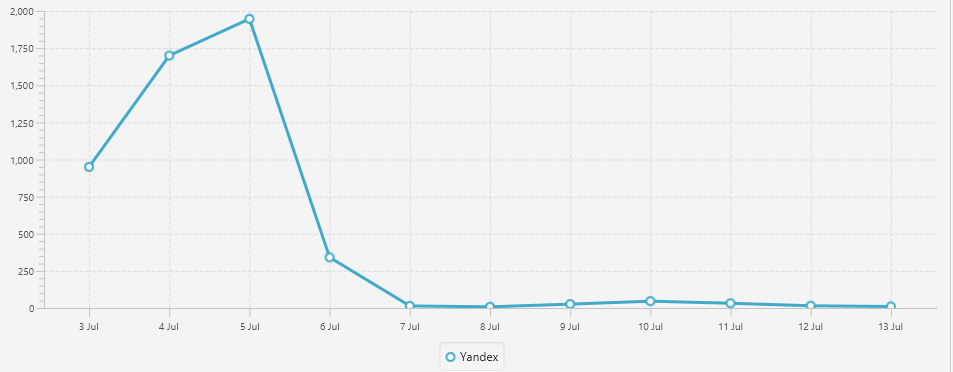
График изменения количества просканированных страниц пагинации Яндексом после указания в robots.txt директивы Clean-param.
Как видно на графике, Яндекс резко забыл о существовании пагинации на сайте. Т.е. как итог — метод практически равносилен закрытию от индексации. Мы не запрещаем ботам сканировать страницы, но и желания у него их сканировать тоже не возникает. К примеру за период с 17 по 22 июля Яндекс обошел 3 страницы.
Как же поступать в итоге?
Быть может я многих расстрою своим ответом, но не существует единого способа оптимизации пагинаций. Придется включать голову и выбирать, экспериментировать (SEO — это всегда эксперимент).
Я лишь продемонстрирую несколько примеров, где так или иначе придется включать голову, а не просто прочитать чей-то гайд и поставить каноникал на первую страницу.
- Сайты с так называемой фасетной навигацией (перемножение различных свойств фильтров между собой и создание за счет этого большого числа страниц с комбинациями этих фильтров) за счет большого количества посадочных страниц с разными товарами имеют относительно хороший доступ ко всем товарам сайта через эти посадочные страницы. Следовательно, такие сайты могут вообще отказаться от постраничной навигации и использовать бесконечную прокрутку, либо изменять внутреннюю перелинковку пагинатора (об этом во втором примере) или ограничиться несколькими страницами пагинации даже если на самом деле их больше.
- Пример с категорийным спросом. В ювелирной тематике основной трафик категорийный (купить кольцо, кольца из красного золота с бриллиантами и пр.). И тут нет большой необходимости в постоянном и хорошем обходе поисковыми ботами карточек товара (потому что на них маленький спрос). Тут тоже может использоваться бесконечная прокрутка, или сокращение количества ссылок на страницы пагинации. Например, известный бренд «Санлайт» и сайт «585золотой» не отказались от пагинации полностью. В их каталогах интернет-магазина есть всего одна ссылка на следующую страницу, а не классическая навигация с большим количеством ссылок.
- В тематиках, где товарный спрос очень большой, стоит задуматься не только над методом индексации/сканирования страниц, но и о глубине клика до товаров, размещенных на глубоких страницах пагинации.
То есть речь о том, чтобы оптимизировать внутреннюю перелинковку пагинатора таким образом, чтобы боты в 2-3 клика могли перейти например сразу с первой на 80-ую страницу, при том, что 80-ая страница не последняя. Тут могут использоваться реализации логарифмических пагинации, изменения шага пагинатора и тд. Подробнее стоит почитать в исследовании Audisto — Блог Audisto
ИТОГО:
Далее я приведу кратко все указанные выше методы с их особенностями.
- noindex, follow
- контент на страницах доступен для сканирования;
- со временем гугл перестаёт сканировать содержимое;
- canonical на первую страницу
- корректно для Яндекс;
- создает «скачки» в индексе Яндекс;
- создаёт препятствия для быстрой аналитики индексации сайта;
- некорректно для Google.
- canonical сам на себя
- корректно для Яндекс;
- корректно для Google;
- в неопытных руках может привести к усилению конкуренции между страницами в поиске (больше в Яндекс);
- Не пользуюсь этой возможностью, но стоит упомянуть, что при этом методе возможна оптимизация страниц пагинации под различные НЧ поисковые запросы.
- canonical на view all
- корректно для Google;
- сложно реализуемо на сайтах с большим ассортиментом.
- закрытие от индексации и динамическая пагинация
- может применяться, если вы понимаете риски с этим связанные.
- clean-param в яндекс
- корректно обрабатывается ПС Яндекс и приводит к отсутствию пагинации в индексе. Страницы и контент на них обходятся поисковыми роботами, но редко.
Вопрос-ответ
Закрывать ли страницы пагинации от индексации?
К сожалению однозначного ответа на этот вопрос нет. Чаще всего пагинацию не стоит закрывать от сканирования и индексации. Я думаю, прочитав данную статью вы сможете ответить на этот вопрос самостоятельно.